
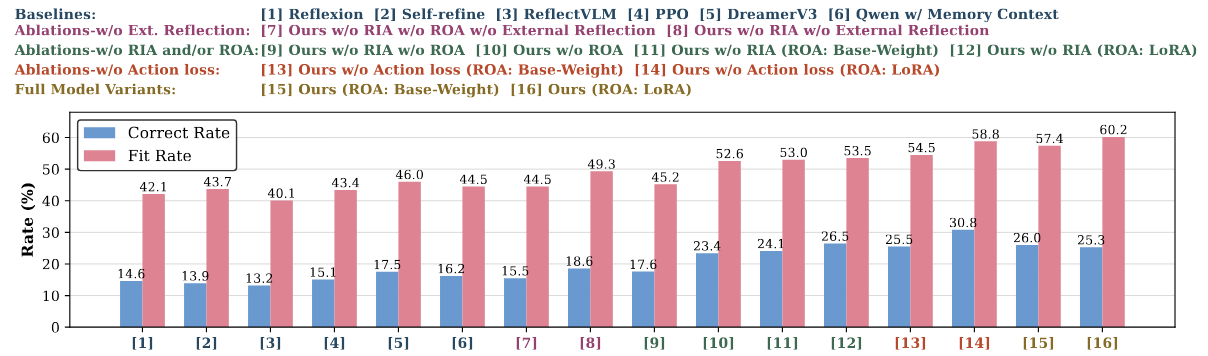
Embodied LLMs endow robots with high-level task reasoning, but they cannot reflect on what went wrong or why, turning deployment into a sequence of independent trials where mistakes repeat rather than accumulate into experience. Drawing upon human reflective practitioners, we introduce Reflective Test-Time Planning, which integrates two modes of reflection: reflection-in-action, where the agent uses test-time scaling to generate and score multiple candidate actions using internal reflections before execution; and reflection-on-action, which uses test-time training to update both its internal reflection model and its action policy based on external reflections after execution. We also include retrospective reflection, allowing the agent to re-evaluate earlier decisions and perform model updates with hindsight for proper long-horizon credit assignment. Experiments on our newly-designed Long-Horizon Household benchmark and MuJoCo Cupboard Fitting benchmark show significant gains over baseline models, with ablative studies validating the complementary roles of reflection-in-action and reflection-on-action. Qualitative analyses, including real-robot trials, highlight behavioral correction through reflection.
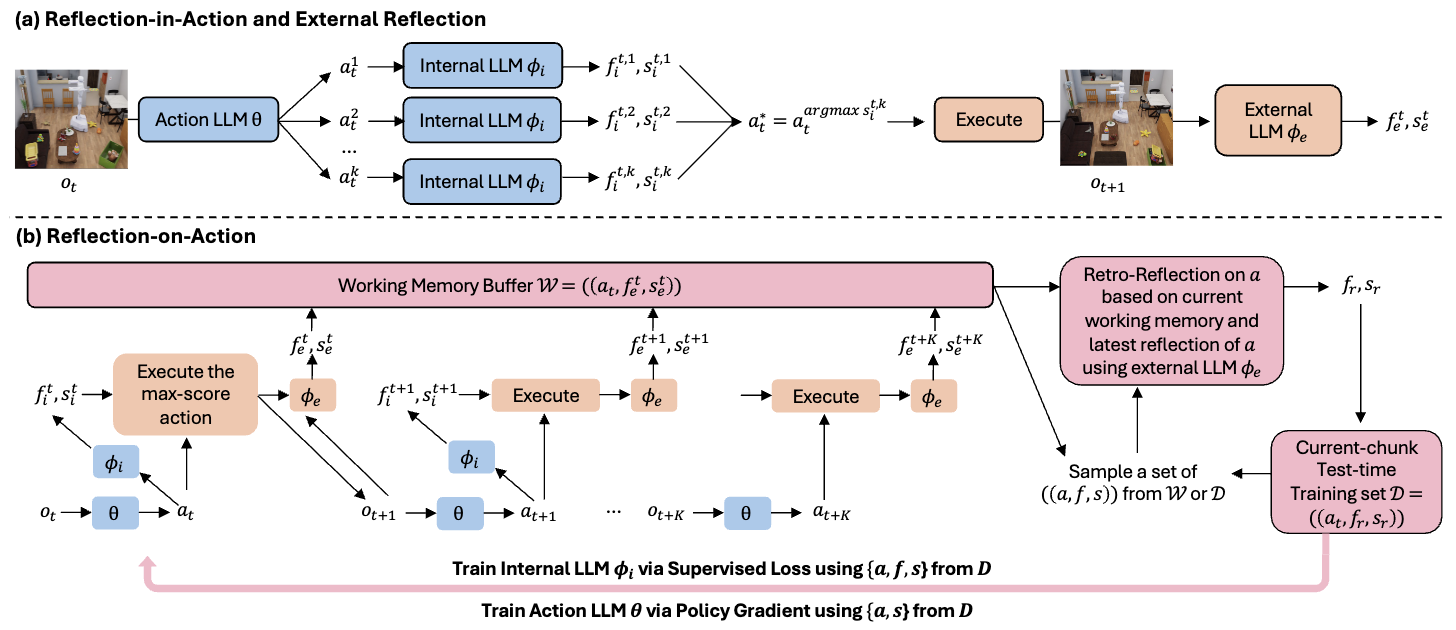
Method overview. (a) Reflection-in-action: multiple candidate actions are generated and scored by an internal reflection LLM prior to execution. (b) Reflection-on-action: iteratively invoked when working memory hits K or at key milestones. Executed actions are critiqued by an external reflection LLM and stored in a working memory buffer; at milestones, hindsight re-evaluation assigns long-horizon credit. The resulting verbal reflections form self-supervised training data to update both the internal reflection LLM (supervised loss) and the action LLM (policy gradient) via test-time training, enabling agents to learn from execution experience during deployment.

@misc{hong2026learning,
title={Learning from Trials and Errors: Reflective Test-Time Planning for Embodied LLMs},
author={Hong, Yining and Huang, Huang and Li, Manling and Li, Li Fei-Fei and Wu, Jiajun and Choi, Yejin},
year={2026},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={http://arxiv.org/abs/2602.21198}
}